


Gourmet Literature Review
How to find every single piece of academic literature on a topic you know nothing about yet. 3 tools and a strategy.

My Blog has moved
If you want to receive updates, new content, and tips, check out my website.
As an interdisciplinary scientist, I had to go into unknown fields a few times.
In a new field, you don’t even know, what you don’t know - so what to search for?
This is where a few modern tools come in handy. In this tutorial, we will learn how to get the most relevant papers from a domain we nothing about.
This will save you a lot of time and increase the quality and speed of your learning.
Announcement: On Saturday January 28th I am teaching a 2 hour workshop. More than 500 hours of experimentation on the topics of this newsletter condensed into 2 hrs. Plus you get access to a private Discord community to learn directly with me. Price is 15$.

If the time does not suit you, there will be a recording as well!
End of announcement - Now back to literature review!
From Idea to Seed
Papers are connected by citations. To find the first few, we would usually use Google and type in e.g. “Forest succession” (succession describes how forests evolve over time). Downside: You will get a lot of irrelevant, non-academic material.
Instead: Try Open Knowledge Maps (or OKM). Type in your topic and get a list of papers sorted by category.
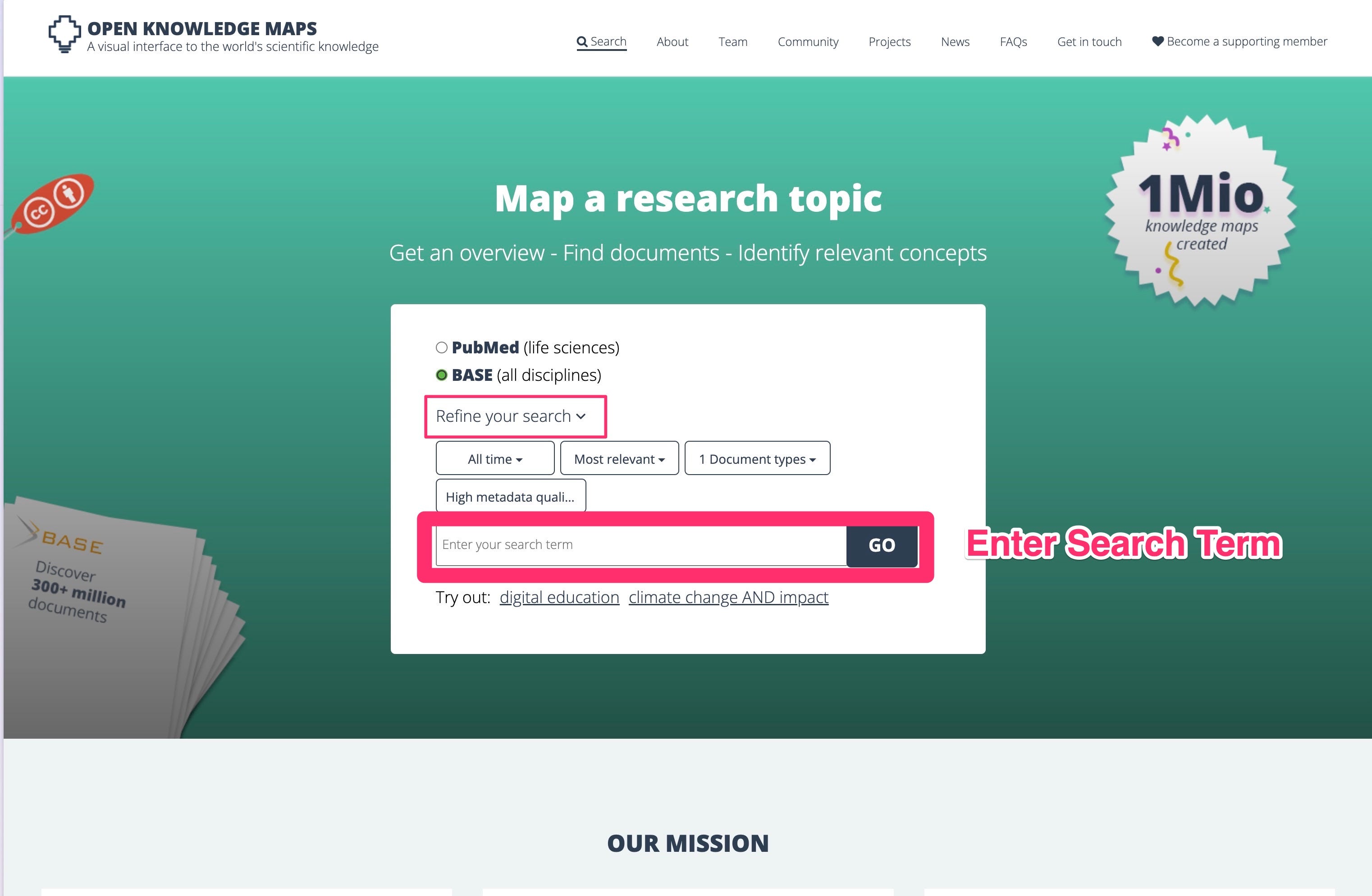
That sorting by category is why I like OKM so much.
In the top right corner you can narrow down your search. For example you might want to be interested in succession of tropical forests. So type in “tropical”.
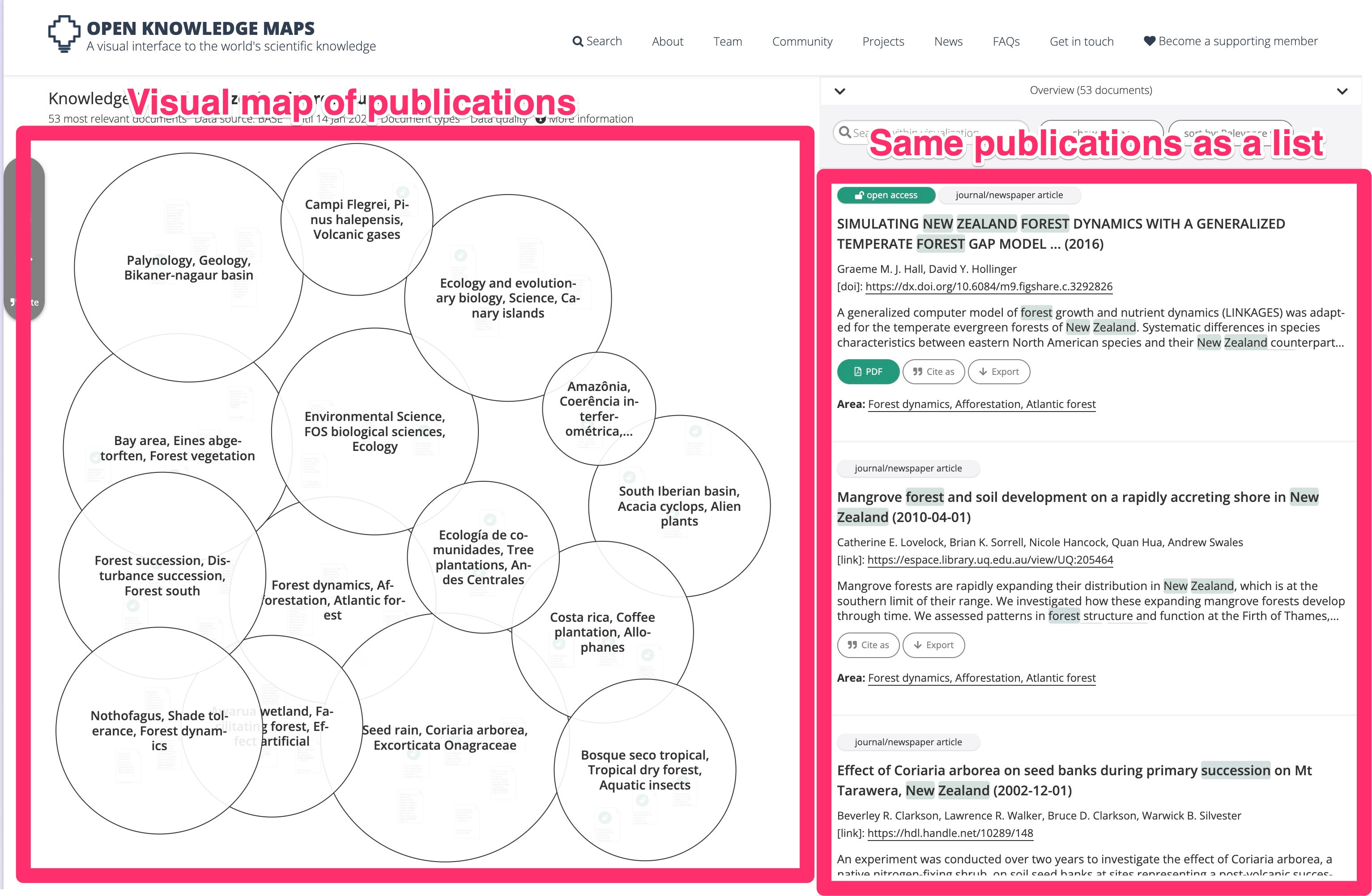
Each bubble contains a set of paper in this category.
It is a great little tool, for this first step of research - but it is not exhaustive. (The map here shows only the 53 “most relevant” papers.)
OKM also does not know all the papers out there. The co-founder of Policy Commons, Toby Green pointed out to me that their search engine finds “grey literature”. This refers to publications from e.g. NGOs that doesn’t find its way into traditional academic journals and is thus hard to find.
Check it out, especially if your domain is politics, social sciences or economics.
Collect your papers
Let’s say you used OKM and found a few papers. You can write it down, but there are better ways: Reference Managers.
Zotero is the most common reference manager. I find its integration is not as “smooth” as it could be.
A better solution for me is PaperPile (3$/mo for academics). I like it because it integrates beautifully with the browser.
In OKM you can right-click and add to Paperpile. (I tried with Zotero and while it will capture the DOI link, it is not smart enough to recognize that it is a paper; stores as website instead).

Paperpile integrates into many other websites as well. Most notably into google scholar and anywhere where you might see a DOI link. Super convenient!
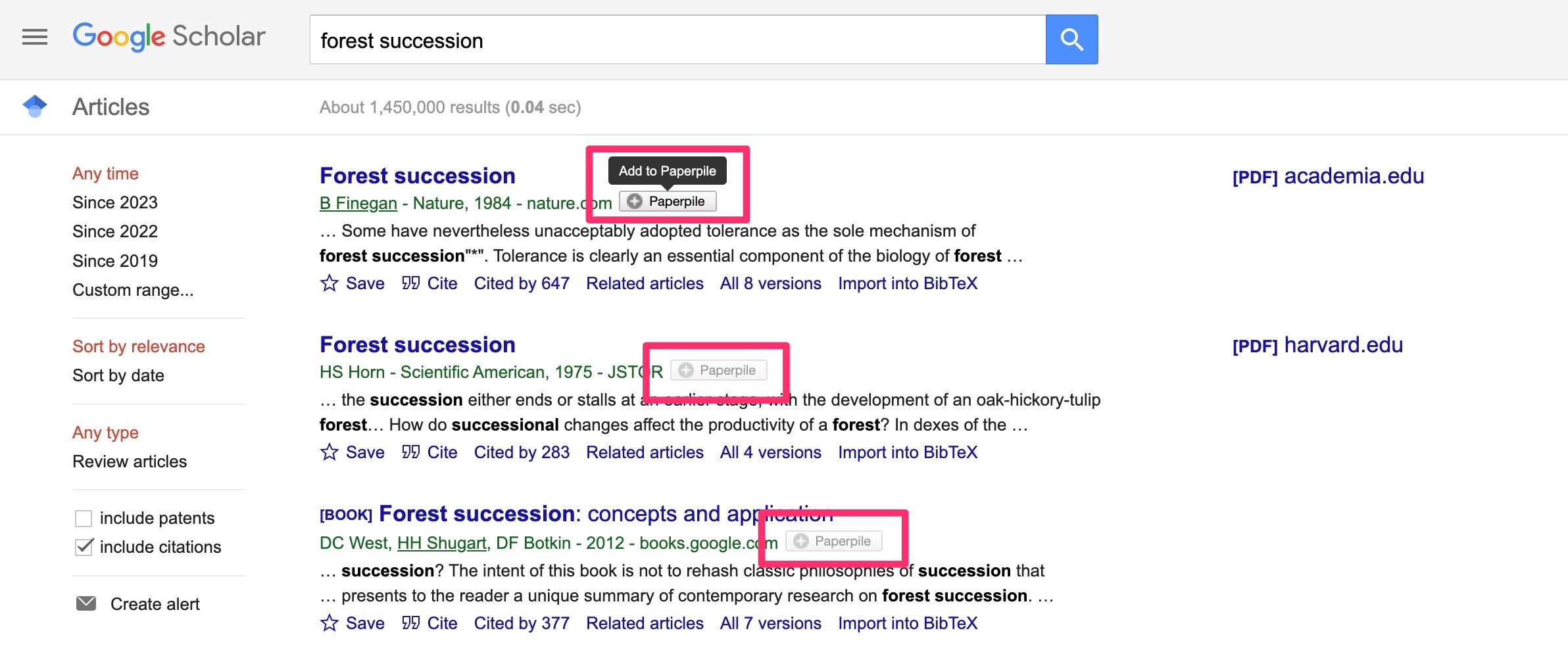
Some other reasons why I like it:
It’s easy to assign tags to papers, by just dragging them onto the papers.
It auto downloads PDFs.
You can generate a public link of your collection. Useful if you are a professor and want to share relevant literature with your students.
The core takeaway is: Use some Reference Manager to store your seed papers.
From Seed to Everything
Now we have a few seed papers and we want to find ALL papers that co-cite together. The most frequently used tool for this is ResearchRabbit. Personally, I find it overwhelming and unintuitive. Sorry!
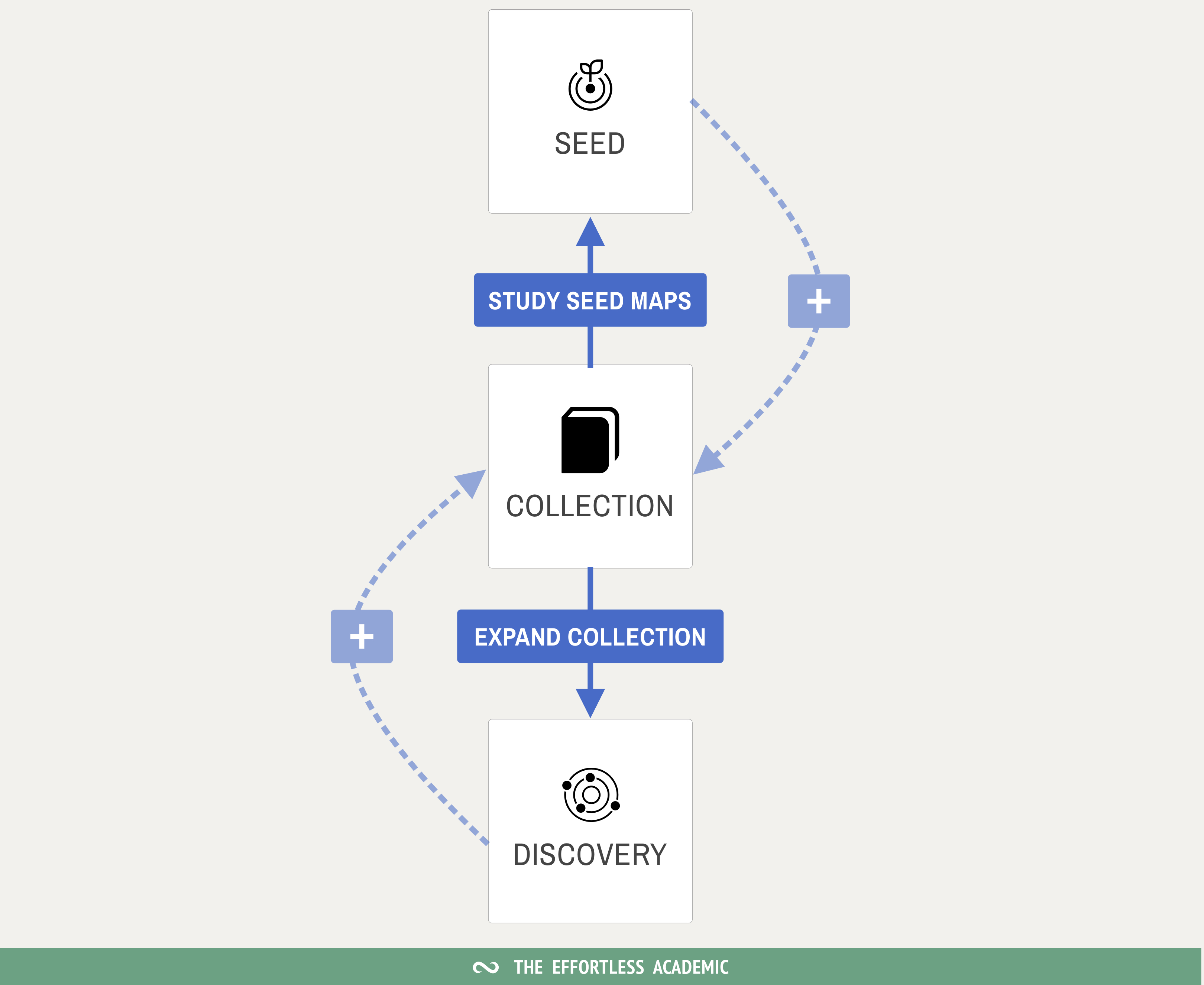
What I use is Litmaps (~10$/mo, but the free version will get you very far as well). I like it because it has 3 features that work well together:
Seed Maps: Given a single paper finds most connected papers, earlier and later in time.
Discovery: Given a set of papers finds other papers that would fit into the set.
Visualization: Displays a set of papers as a graph by time, citations, and number of references. Allows you to rearrange things and share the result.
The first step will be to import the seed papers we collected previously and add them to a Litmaps “collection”. Here are my 5 example seed papers:
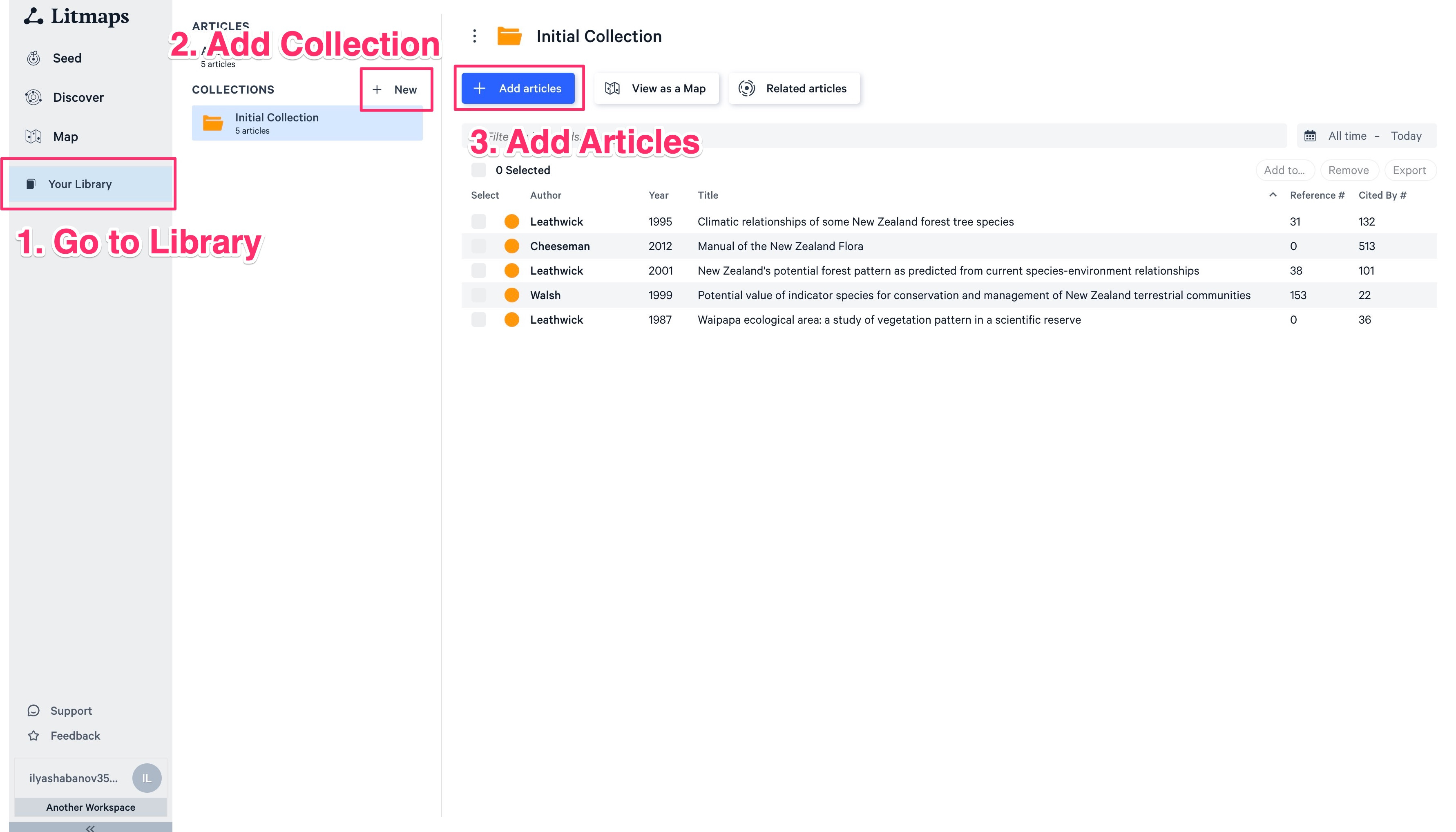
A collection is just a folder for your papers. You can add papers by name, and DOI or export them from Zotero/Mendeles/Paperpile and import them to Litmaps. (Note: we don’t upload PDFs, it is just the reference we are dealing with here.)
Using Seedmaps
Click on any paper you imported and select “View Seed Map” to get started.
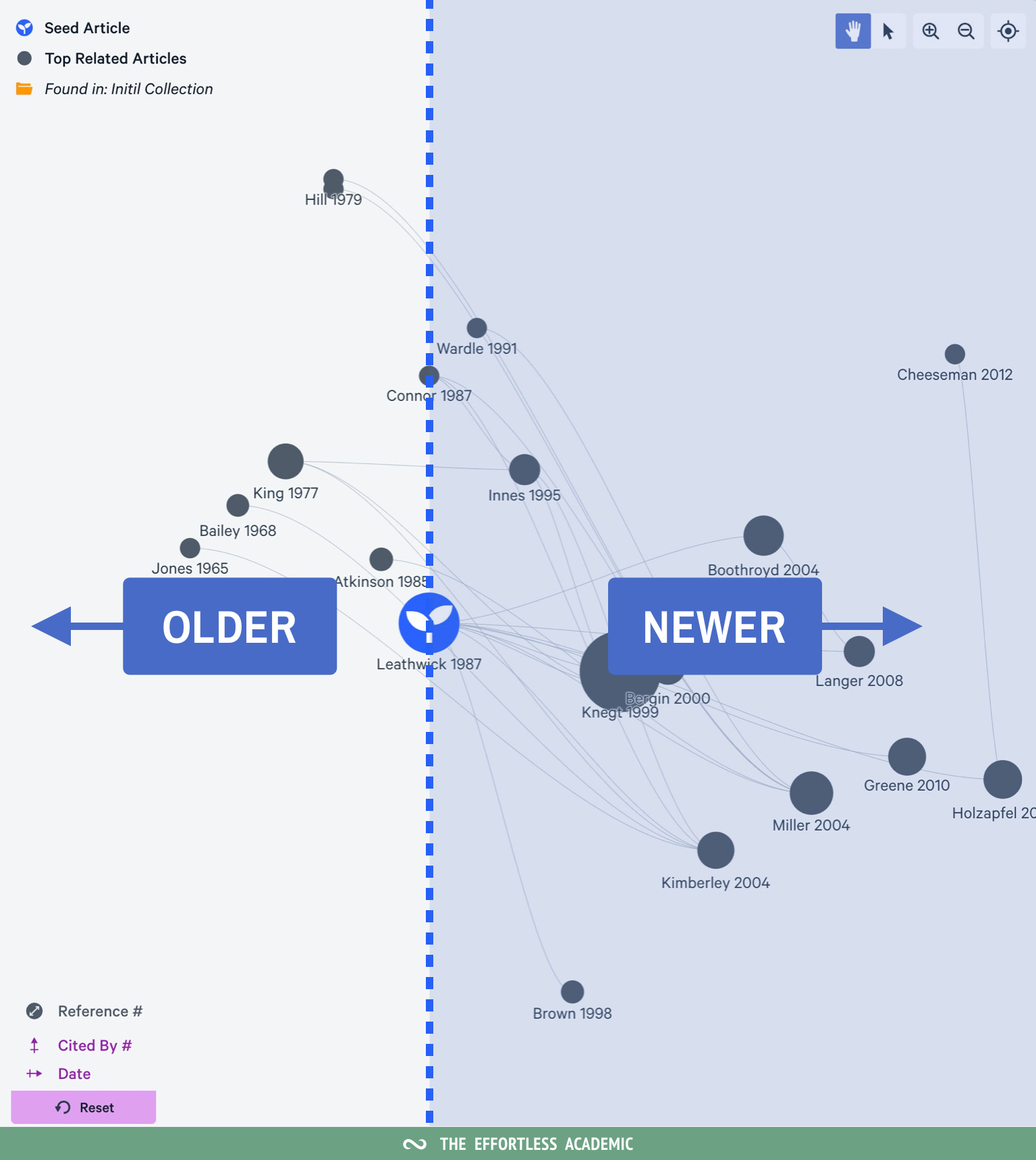
Now you will see papers in a graph. With your seed paper in the middle. Note the legend at the bottom left, it defines what the axis represents. (If you have different settings, click to change them, so this tutorial makes sense).
The first thing to note is that the X-axis displays papers by age. If you are looking for recent literature look right, for foundational literature look left.
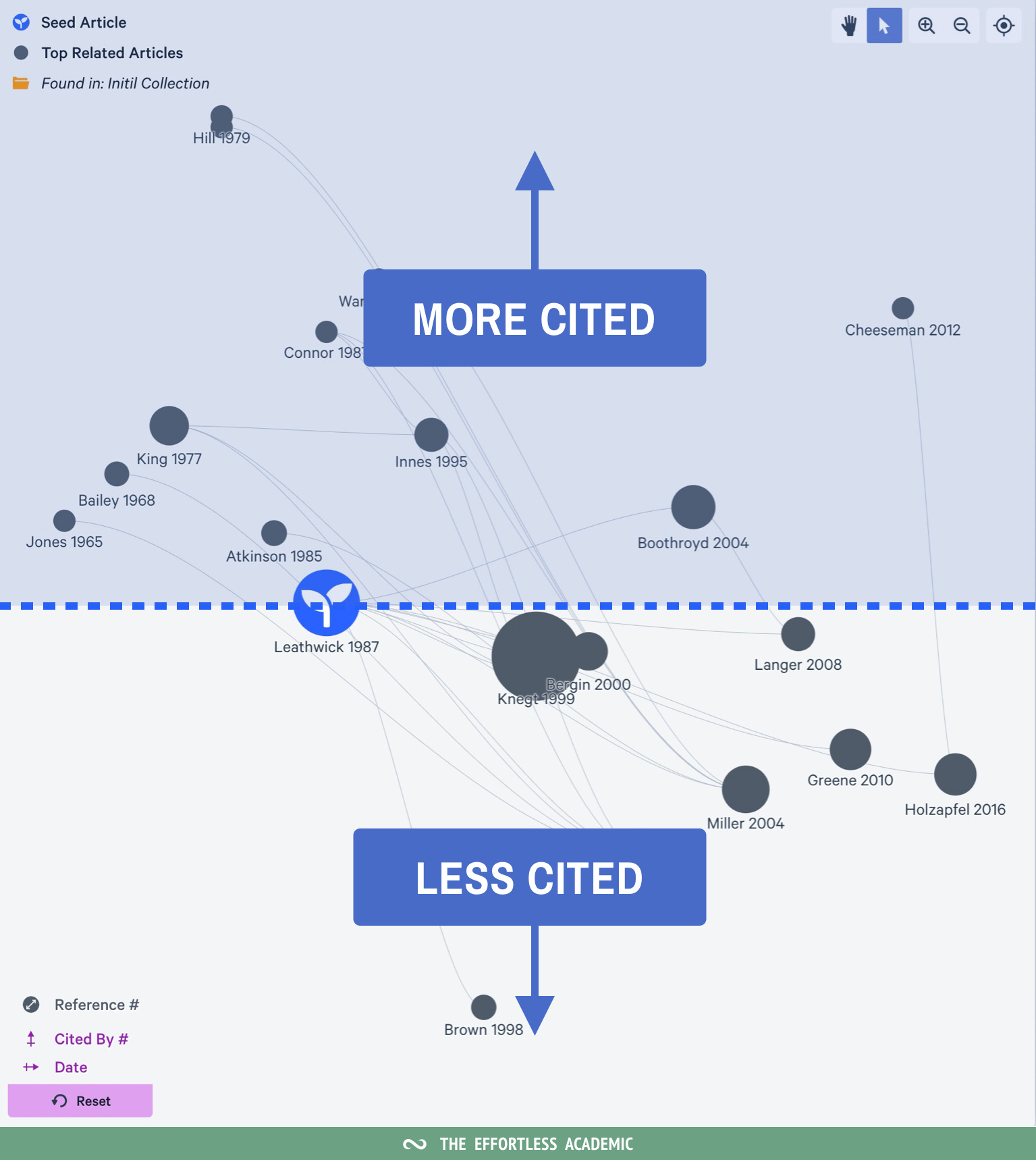
The top and bottom of my configuration show more or less cited papers.
Citations are arguably not the only metric to look at when finding good papers.
But citations will usually have a negative correlation with age - the older a paper the more citations. In other words, papers will sit on a diagonal from top left to bottom right.
This allows you to look for outliers: something that is right of the diagonal. These are papers that are highly cited AND new. Meaning they made an impact on the field quickly.
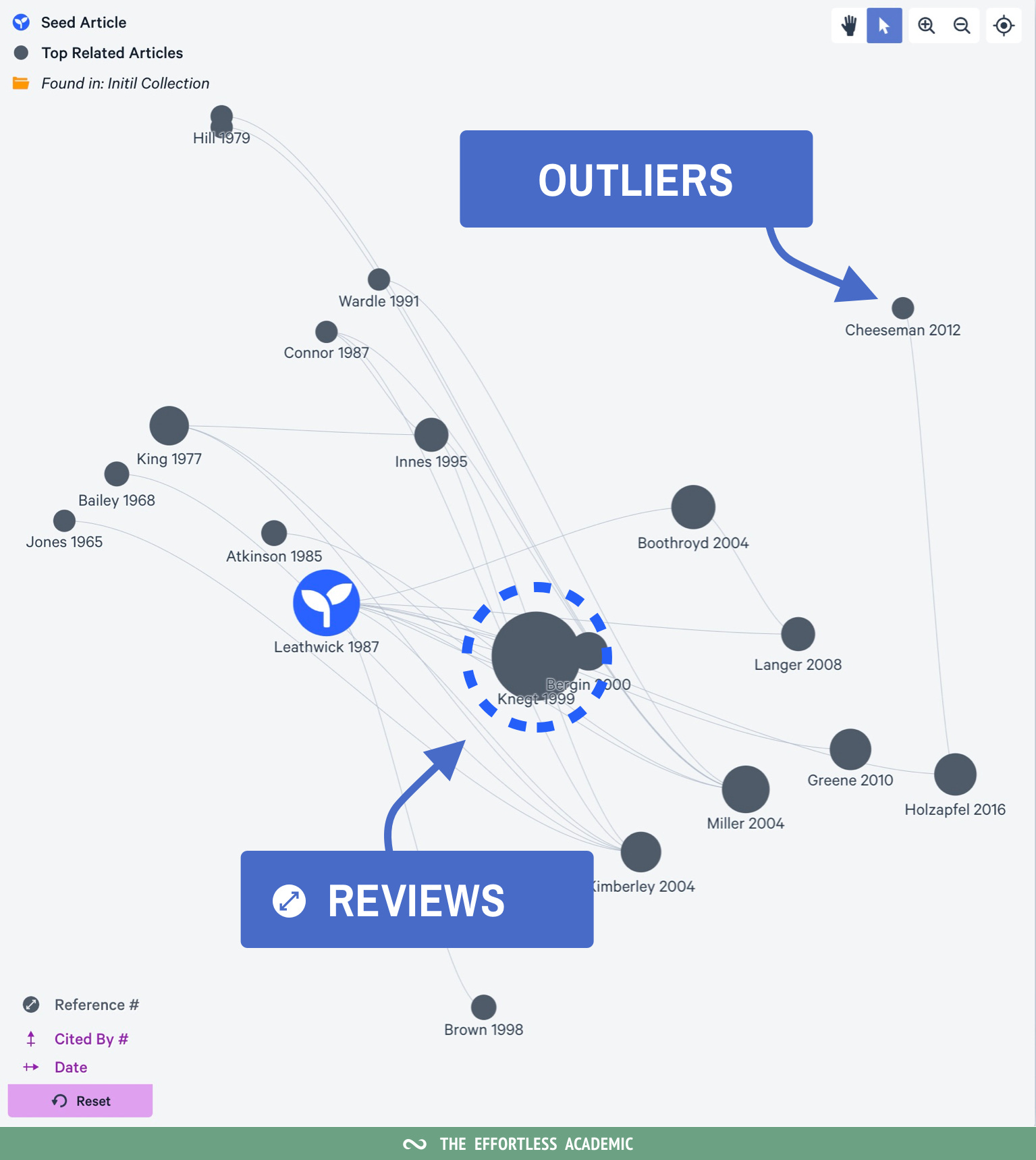
The last setting is the size of the circles. It shows you how many references a paper has. Review papers will often have many more references than “regular” papers. So you can identify them quickly, by looking for big bubbles.
If your review is additionally off the diagonal - you probably have a must-read paper.
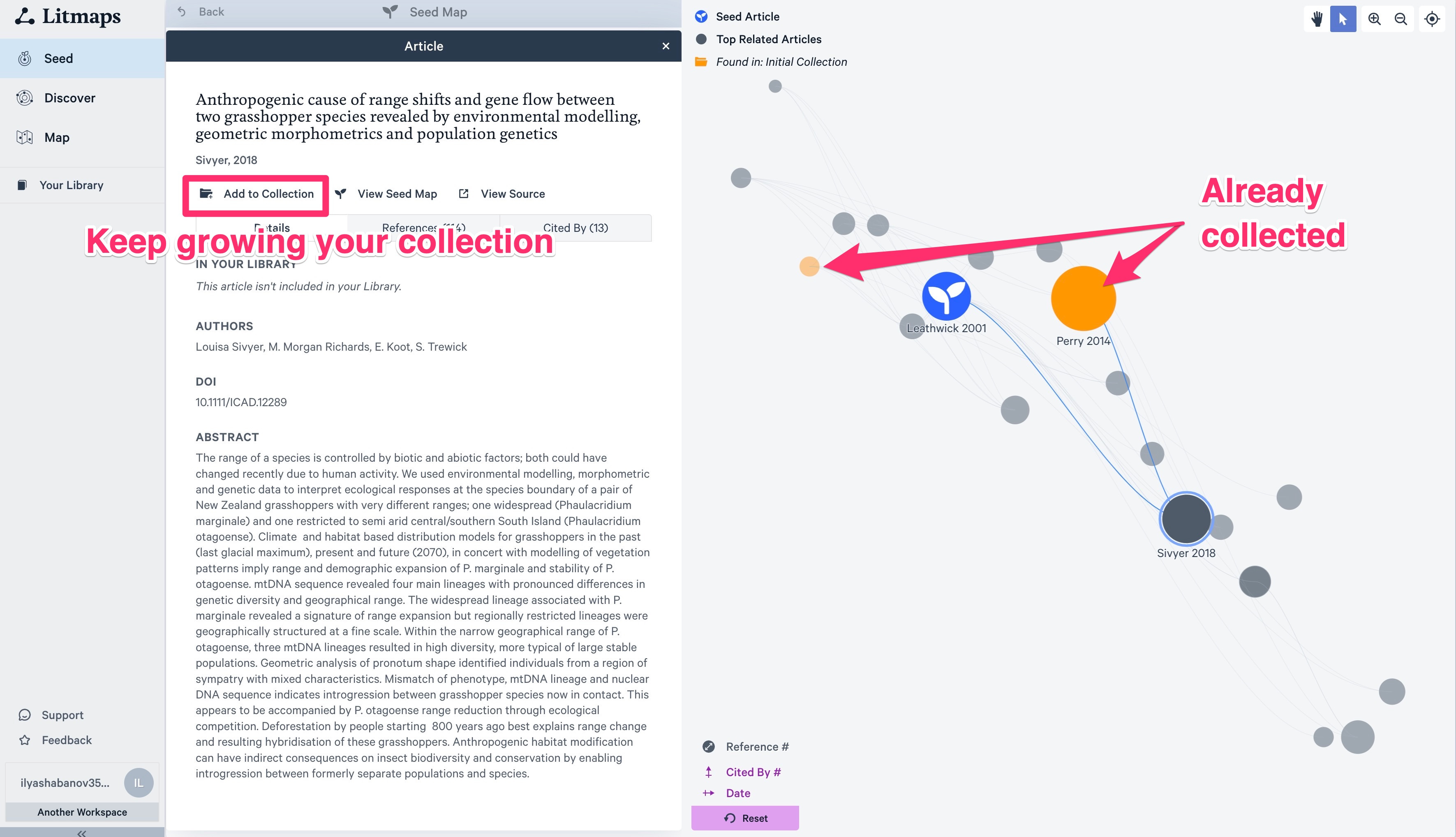
Click on the circles, explore abstracts, and add what seems relevant to your growing collection of papers. (Don’t be too selective, as we will sort papers out later!)
Recursively look at the seed maps of the new papers.
After adding a paper to your collection it will be shown in a different color. And eventually, you will see that your searches start to return more and more of what you have already seen.
Discovery Mode for an exhaustive search
When you have a set of papers you can instead or additionally use the Discovery mode to find new ones. Click on “Discover” on the left-hand side menu and add your collection.
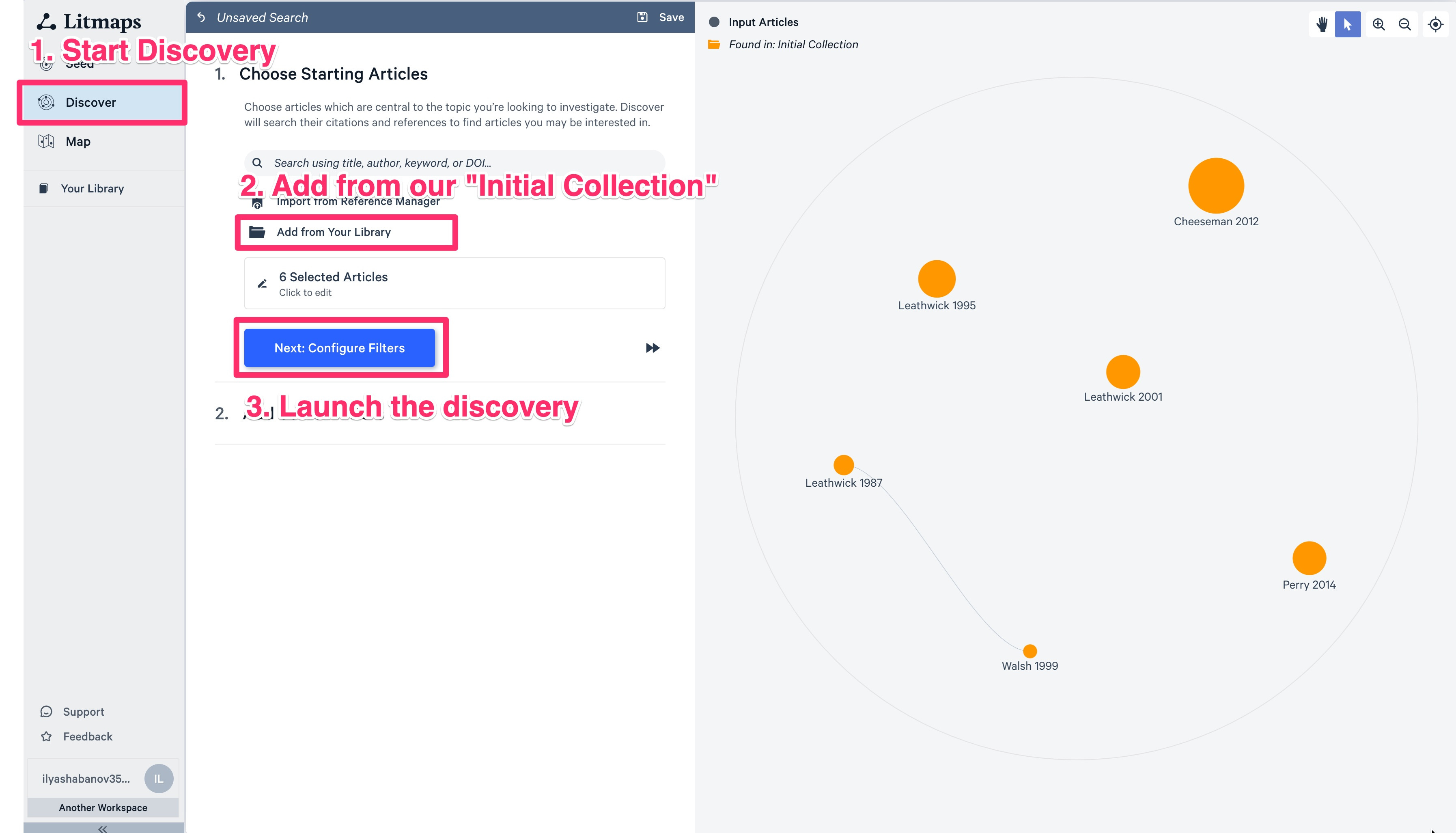
What you will see, is a network of your papers. If two papers are connected, the newer one cites the older one.
On the outside, you will see the papers that share references with your collection. You can identify papers that “your collection is collectively citing”.
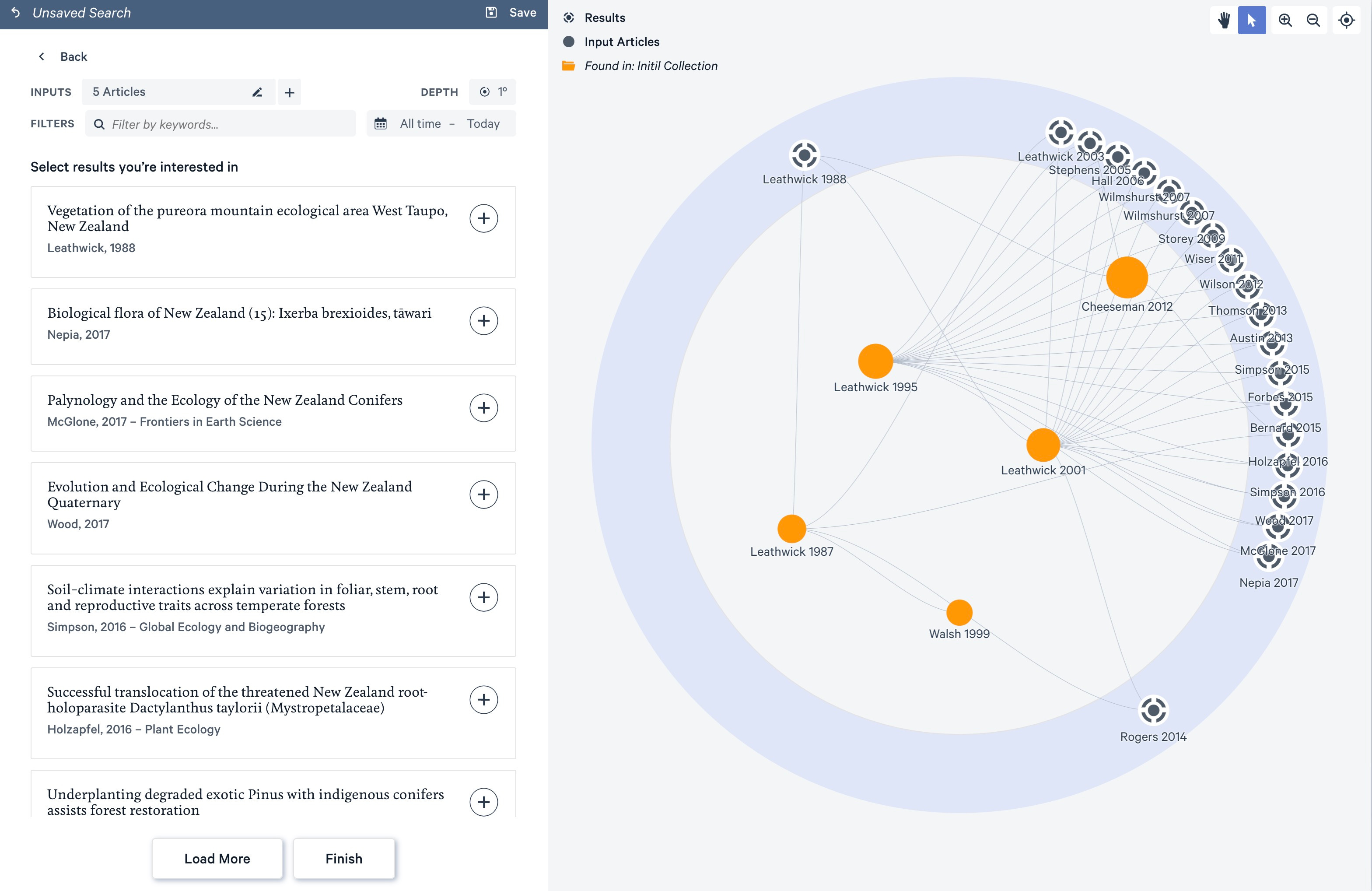
On a paid plan you can also see 2nd-degree citations, but this feature is slow and frankly unnecessary (as you can add papers to your collection and rerun the search, with a similar end result).
Discovery allows you to add papers to the search: Click on the “+” buttons and hit “Load More”.
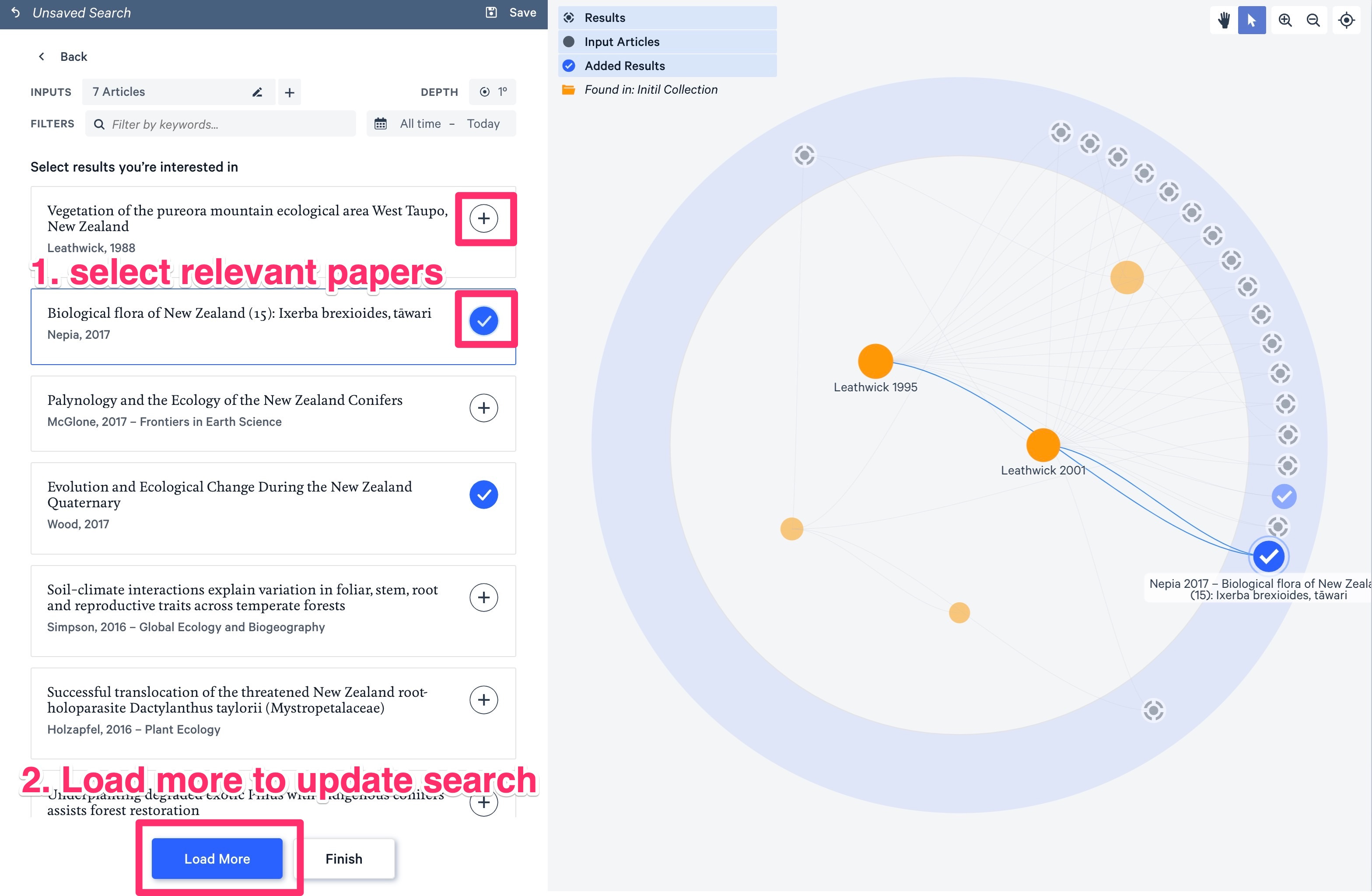
The search will rerun and your results will (more or less) change. Check out how all these papers at the bottom appear, after I added the other two:
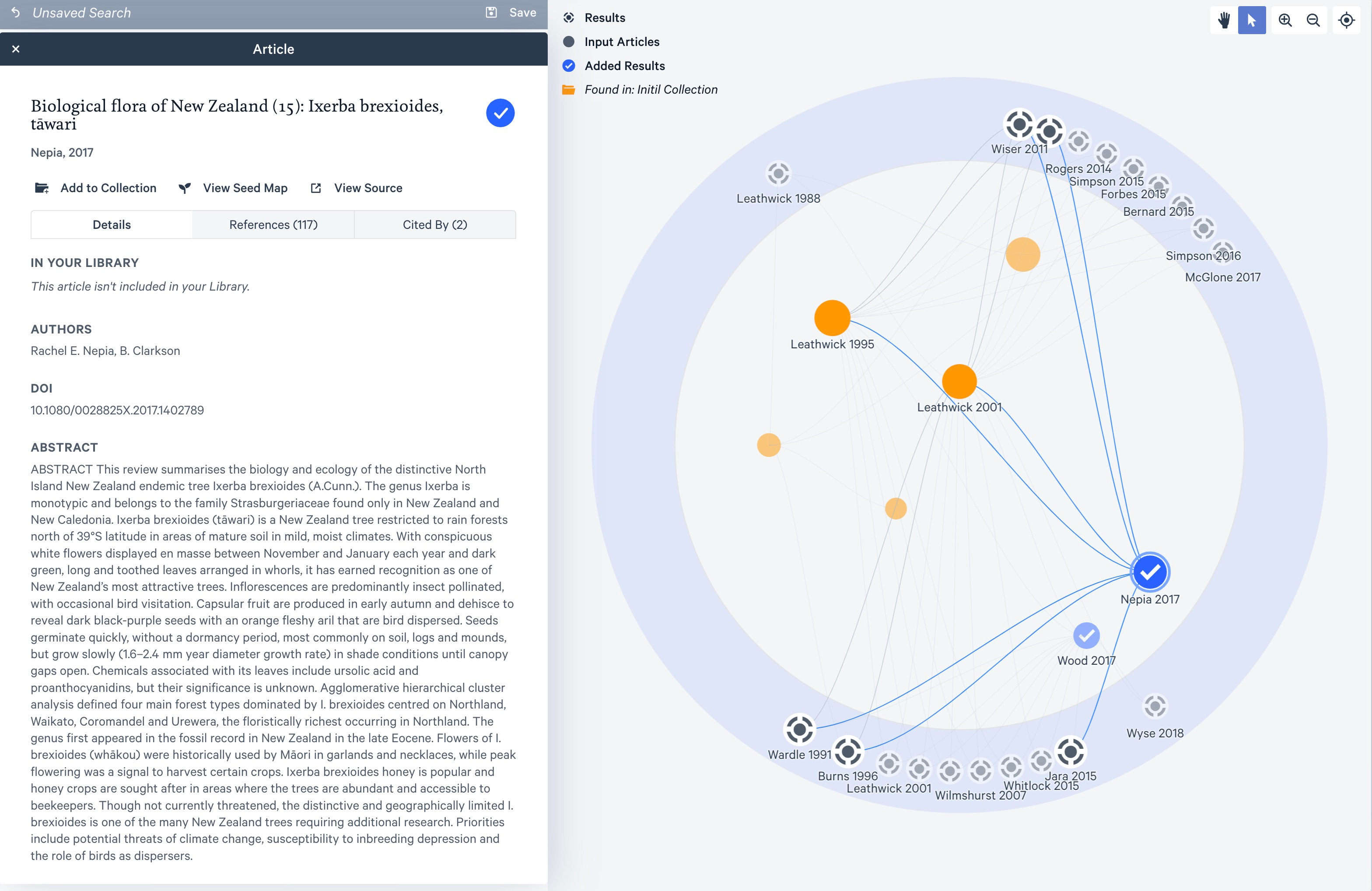
Adding papers to the search does not add them to your collection. You have to do that manually. (Add to collection button, on top left, of the Article panel).
Pro Tip: If you have a search set up, you can ask Litmaps to notify you as new papers become available. A neat way to stay in the know, especially in multidisciplinary research.
Seed → Discovery → Seed
Look at the Seed Maps of the papers you found in discovery and repeat until you have found every single paper out there! It’s fun and as you can see at no point is there an overwhelming number of papers. (Exactly the reason why I prefer Litmaps over ResearchRabbit).
Trim your collection: 3-Cut-Technique
You probably ended up with a 1001 paper that you won’t have time to read. That’s ok - let’s pick out the most impactful ones.
Go back to your collections and create a new collection that we can call “Reading List”, we will add the most relevant papers from our search here.
The first “cut” is to find the most recent literature. To do that sort by year and pick a few of the top papers in the list. Then add to your “reading list” collection.
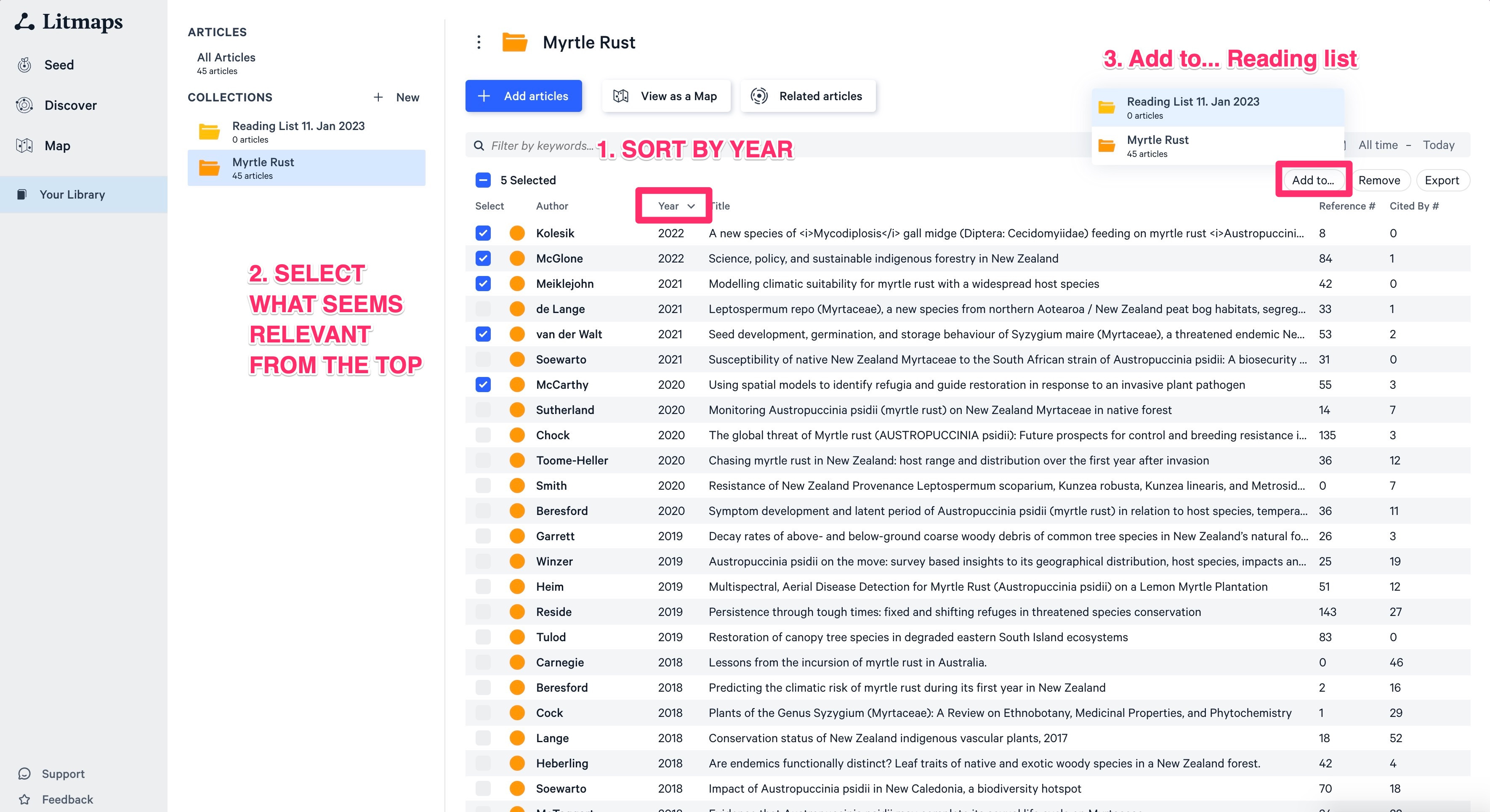
Of course use your best judgement what is relevant and what not. A rule of thumb could be to use top 10% of papers. (This way you will end up with at most 30% of your initial collection after all 3 cuts).
The second cut is by citations. We will find the most cited papers. Sort by citation and again select the top ~10%. Arguably the most impactful papers in the field.
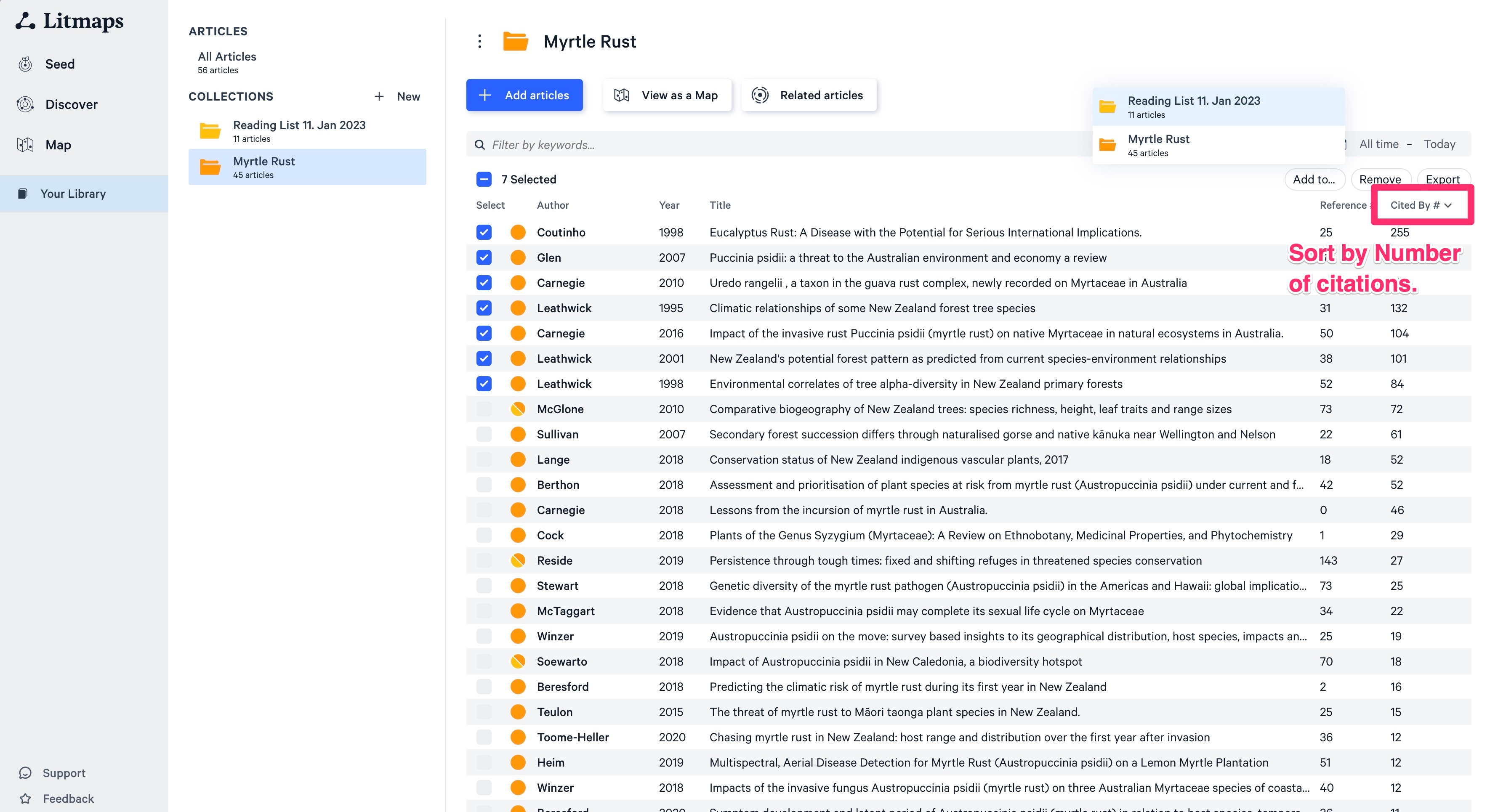
The third cut is by the number of references. This allows you to identify papers that have very beefy introductions or are review papers. I would read those first if I don’t know anything about the domain.
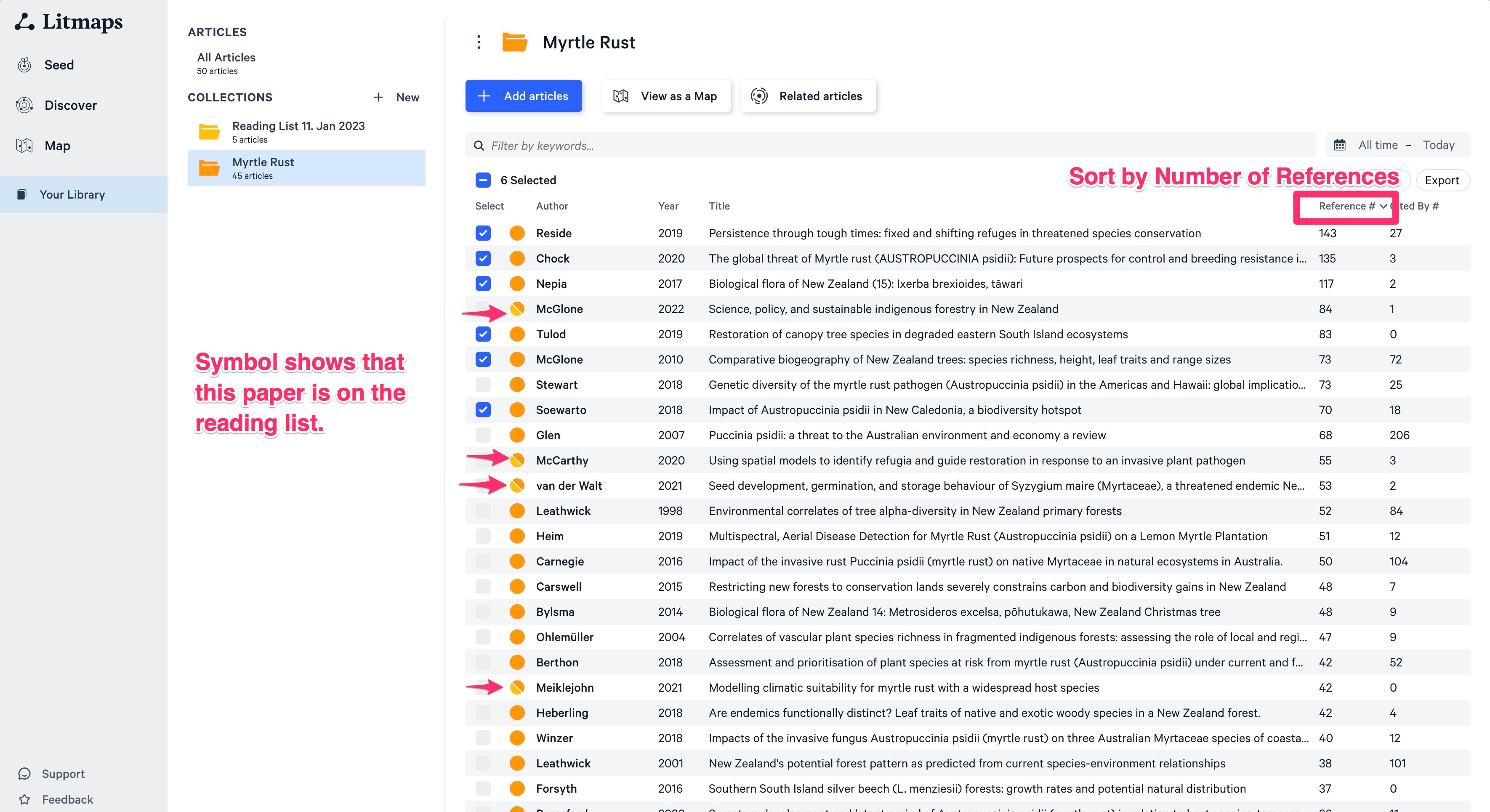
Notice also that the color will show you if a paper is in multiple collections. Papers that are for example top cited AND recent can be already identified this way.
Visualize your collection for order
Likely your collection has shrunk a bit by now - you prioritized!
Let’s do one last step to really see where we are at and pick the paper we want to read today! Click on “View as a Map”:
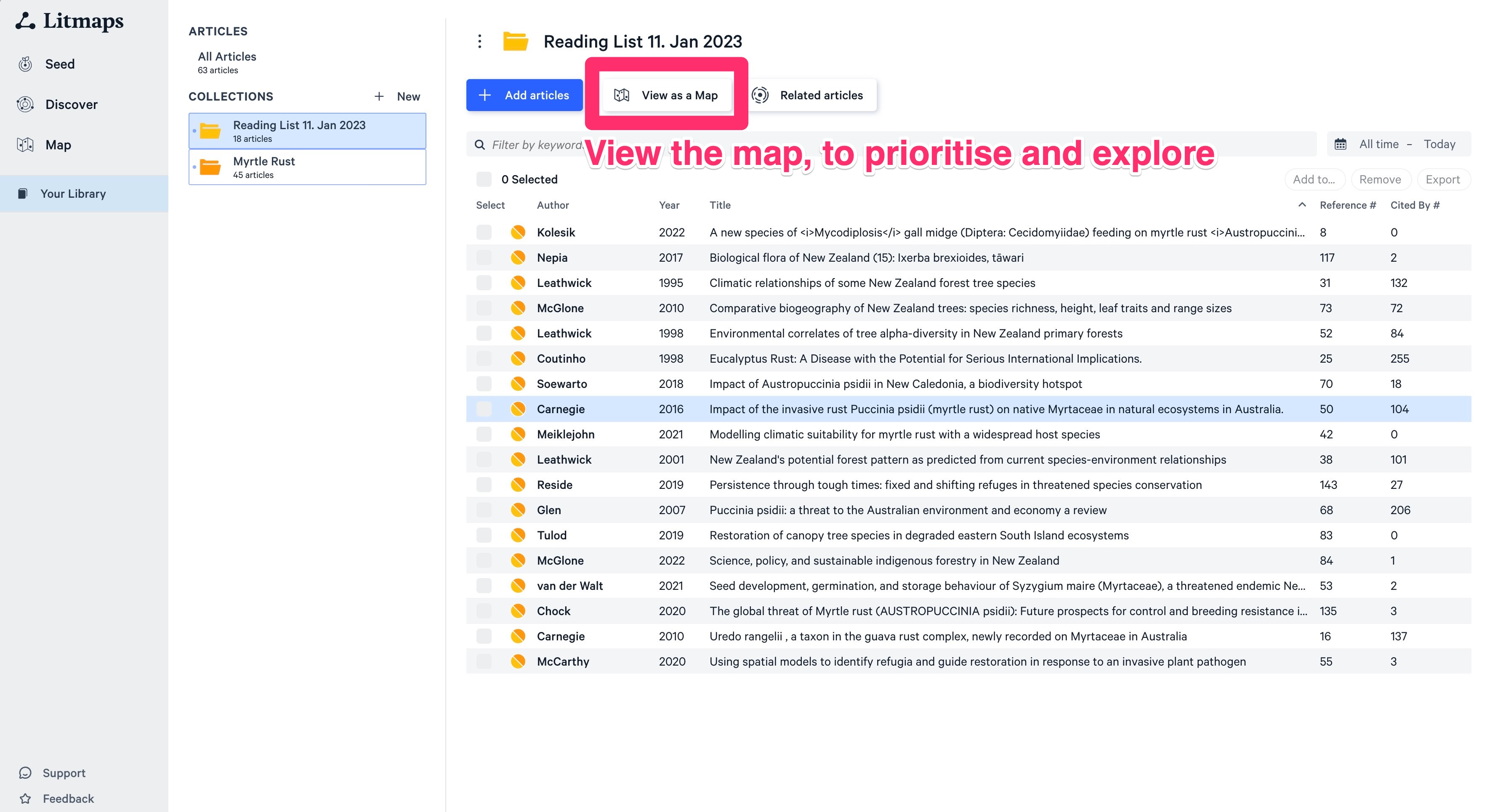
The resulting graph will be familiar to you - it is structured in the same way as the seed maps above.
You can do the same type of analysis. But what I like about it is that you can MOVE the papers around (and even select multiple, like in a RTS game). Sort them visually however you want by moving them around.

That map in its current state can be shared with your student or PI. Isn’t that just pure luxury? (The share button on the top right)
Reading the papers
Well now to the difficult part: Reading!
I can’t really help you with that, but I can help you with taking better notes as you read.
Using the SCTO system of note-taking will bring structure into your reading-synthesis-writing workflow. Additionally, you can manage your notes visually to establish connections between the papers.
I have spent 500+ hours developing this system for my own research. If you want to learn everything I know in 2 short hours: Join my workshop on Jan 28th.

Summary
In this tutorial you have learned to collect a seed set of papers using Open Knowledge Maps and PaperPile.
Then used Litmaps Seed Map feature to analyse all of them and collect more related literature.
Plugged the resulting set into the Discovery feature to find even more remote, co-cited papers.
And lastly used the 3-cut-technique to trim your collection to 10% most recent, 10% most cited and 10% review papers.
I hope you enjoyed this tutorial and please comment any questions below.
Follow me on Twitter, if you aren’t already. Smooth sailing!
Will you sync back the articles in Paperpile to Zotero? In other words, how to maintain these two software in the same time? Thanks Ilya.